
Em 2023, mais de 578 mil sites adicionaram uma linha ao seu robots.txt para bloquear o GPTBot da OpenAI. Crescimento de zero até meio milhão em quatro meses. Parece uma reação razoável ao surgimento de bots de IA treinando modelos com conteúdo alheio.
O problema: uma boa parte desses sites provavelmente bloqueou também os bots que permitem aparecer nas respostas do ChatGPT Search, do Perplexity e dos AI Overviews do Google – sem saber que são bots diferentes com funções diferentes. O crescimento de 6.900% YoY no tráfego de crawlers de IA significa que essa decisão tem consequências reais. Bloqueou o bot errado, saiu das respostas de IA.
Este guia explica o que é robots.txt, como funciona, quais bots de IA existem, qual a diferença entre busca e treinamento, e como configurar tudo com três templates prontos para copiar.
Pontos Importantes
- robots.txt controla rastreamento, não indexação – uma página bloqueada ainda pode aparecer na SERP
- Bloquear bots de busca de IA (ChatGPT-User, PerplexityBot) remove você das respostas dessas IAs
- Google-Extended não afeta AI Overviews – só controla uso do conteúdo para treinar modelos Google
- ChatGPT-User rastreia a 2.400 páginas/hora – é o bot mais ativo da OpenAI em sites externos hoje
- Sem robots.txt ou com
User-agent: * Allow: /, tudo está permitido por padrão
O que é robots.txt
O robots.txt (parte do REP – Robots Exclusion Protocol) é um arquivo de texto simples na raiz do domínio que instrui crawlers automatizados sobre quais partes do site podem ser rastreadas. Presente em 94% dos 12 milhões de sites analisados em julho de 2025, é o padrão universal para controle de acesso de bots. Não é um mecanismo de segurança: é um protocolo de cortesia entre sites e robôs que bots bem-comportados seguem voluntariamente.
O padrão foi criado em fevereiro de 1994 por Martijn Koster, engenheiro da Nexor, depois que um crawler mal-escrito de Charles Stross causou um ataque acidental de negação de serviço no servidor dele. O nome original era RobotsNotWanted.txt. Em junho do mesmo ano já era padrão de facto adotado pelo WebCrawler, Lycos e AltaVista. Em 2022, foi formalizado oficialmente no RFC 9309 pela IETF, 28 anos depois.
Uma distinção que aparece até no People Also Ask do Google: robots.txt controla rastreamento, não indexação. Se você bloqueia uma URL no robots.txt, o Googlebot não vai visitá-la. Mas se ela já foi indexada, ainda vai aparecer na SERP – só que sem descrição, porque o Google não consegue atualizar o conteúdo. Para remover uma página do índice, a ferramenta correta é a meta tag noindex ou a remoção via Google Search Console – não o robots.txt.
Para ver seu robots.txt atual, acesse seudominio.com.br/robots.txt no browser. Se aparecer um arquivo de texto, ele existe. Se retornar 404, não existe – e isso significa que todos os crawlers têm acesso a tudo por padrão.
Como funciona tecnicamente
O robots.txt é lido de cima para baixo por cada crawler que visita o site. Cada bloco de regras começa com um User-agent e se aplica apenas ao bot identificado. Um user-agent específico (ex: GPTBot) tem precedência sobre o curinga * quando ambos existem no arquivo.
A sintaxe básica: User-agent, Allow, Disallow
Três diretivas formam 90% de qualquer robots.txt:
- User-agent: identifica o bot ao qual as regras se aplicam. Pode ser um nome específico (
GPTBot,Googlebot) ou*para todos. - Disallow: bloqueia acesso a uma URL, diretório ou padrão de URL.
- Allow: permite acesso explícito, mesmo quando há um Disallow conflitante. Tem precedência quando os dois se aplicam ao mesmo caminho.
Exemplo mínimo que funciona:
User-agent: *
Allow: /
Sitemap: https://seusite.com/sitemap.xmlEsse arquivo diz para todos os bots: “tudo está liberado”. O campo Sitemap é opcional mas recomendado – ajuda crawlers a encontrar seu conteúdo mais rápido.
Regras de sintaxe que valem prestar atenção:
- O wildcard
*no User-agent se aplica a qualquer bot sem regra específica - No caminho,
*representa qualquer sequência de caracteres e$representa fim de URL - Linhas que começam com
#são comentários – não são lidas pelos crawlers - Um bloco para um User-agent específico se aplica apenas a ele
O que é Disallow no robots.txt?
Disallow é a diretiva que impede um crawler de acessar um caminho específico. Quando você escreve User-agent: GPTBot / Disallow: /, está dizendo ao GPTBot que nenhuma URL do site pode ser rastreada. O contrário é Allow, que abre acesso explícito a um caminho mesmo dentro de um bloco Disallow mais amplo.
O que robots.txt não faz
O robots.txt não garante privacidade, não impede indexação e não tem validade legal por si só. Bots mal-configurados ou mal-intencionados ignoram o arquivo completamente. A Anthropic e a Perplexity já foram reportadas por renomear scrapers para contornar blocklists – notícia publicada pela 404 Media. Para proteção real de conteúdo, a solução é autenticação no servidor, não regras no robots.txt.
Um bot pode ignorar o robots.txt sem violar nenhuma lei específica sobre o arquivo. O que pode gerar ação legal são outros fatores: violação de termos de serviço do site, LGPD no caso de dados pessoais, ou uso indevido do conteúdo coletado.
Por que o robots.txt importa para sua visibilidade em IA
Em 2026, o robots.txt deixou de ser só uma questão de crawl budget (cota de rastreamento que o Googlebot usa por visita) e passou a determinar se uma marca aparece ou não nas respostas de ChatGPT Search, Perplexity e Google AI Overviews. Apenas 8,92% dos top 10 mil domínios têm alguma regra específica para bots de IA – o que significa que a maioria das empresas está tomando essa decisão sem saber.
Cada answer engine (motor de IA que responde perguntas, como ChatGPT Search, Perplexity e Google AI Overviews) usa bots próprios para rastrear e indexar conteúdo. Se o robots.txt bloqueia esses bots, o motor não tem acesso ao conteúdo e não pode citá-lo nas respostas. Entender por que marcas não aparecem nas respostas de IA passa por aqui antes de qualquer estratégia de conteúdo.
Como cada motor de IA usa seu robots.txt
| Motor de IA | Bot relevante para citações | O que acontece se você bloquear |
|---|---|---|
| ChatGPT Search | OAI-SearchBot, ChatGPT-User | Sai do índice do ChatGPT Search |
| Perplexity | PerplexityBot, Perplexity-User | Sai das citações do Perplexity |
| Google AI Overviews | Googlebot | Sai dos AI Overviews E da SERP tradicional |
| Bing / Microsoft Copilot | Bingbot | Sai do Bing e do Copilot |
| Claude (Anthropic) | ClaudeBot, Claude-SearchBot | Sai das respostas do Claude |
Fonte: Search Engine Journal – AI Crawler User Agents
Entender como LLMs decidem o que citar vai além do robots.txt – mas o robots.txt é o pré-requisito: se o bot não consegue rastrear, a decisão de citar nem chega a ser feita.
O equívoco sobre Google-Extended
Esse é o erro mais comum que vejo circulando em grupos de SEO no Brasil. Google-Extended não é um crawler separado. É um “token de produto” que controla como o Googlebot usa os dados coletados para treinar modelos de IA da Google.
Bloquear Google-Extended:
- Não remove seu site dos AI Overviews
- Não afeta seu ranking na busca tradicional
- Apenas impede que o Google use seu conteúdo para treinar seus próprios modelos
O mesmo vale para Applebot-Extended: não é um crawler, é um modificador de permissões.
Para aparecer nos AI Overviews, o Googlebot precisa ter acesso. Para controlar uso de dados para treinamento, você pode bloquear Google-Extended. São dois controles independentes.
Os principais bots de IA que visitam seu site
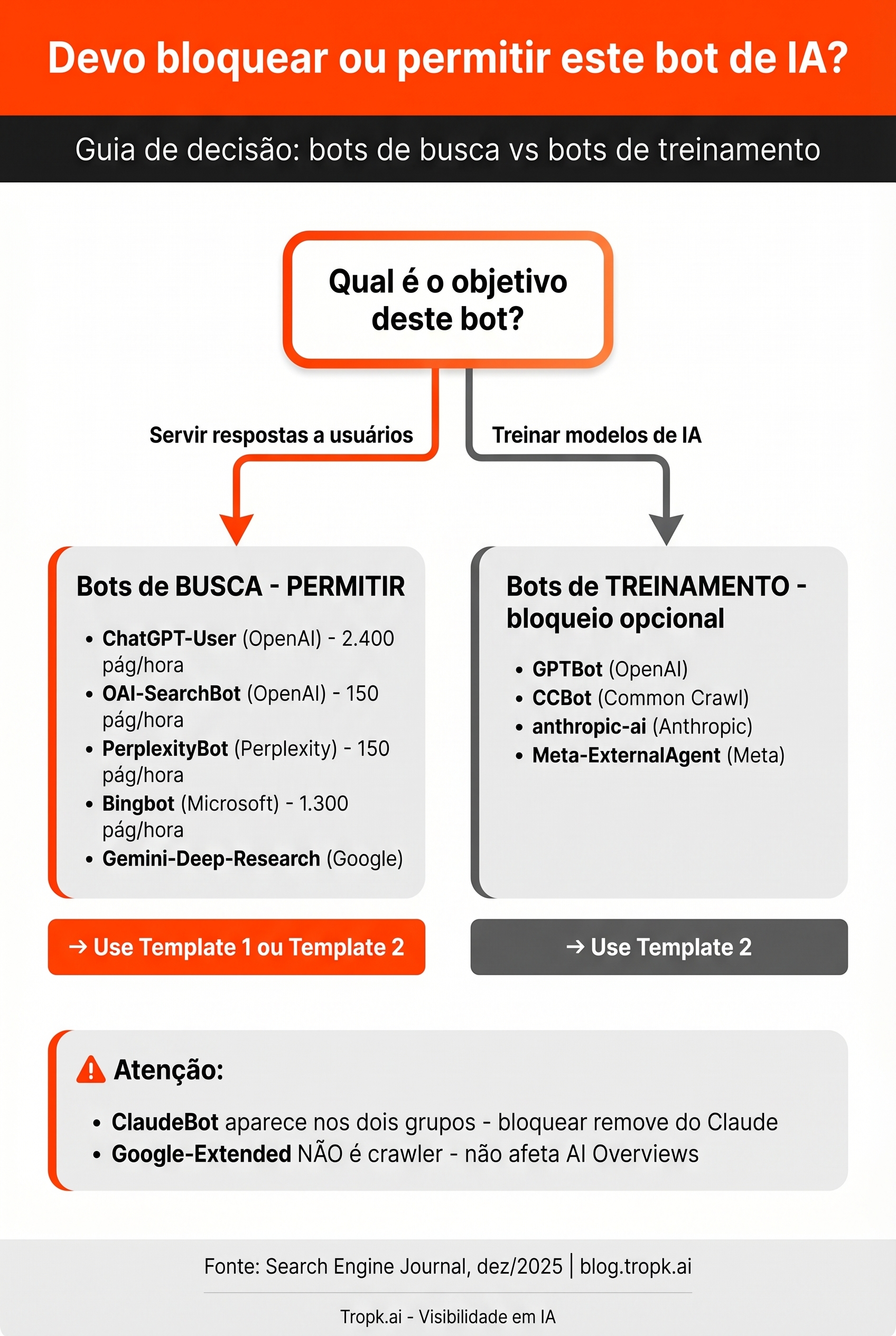
Os bots de IA se dividem em dois grupos com propósitos opostos: bots de busca/indexação (que rastreiam para servir respostas aos usuários) e bots de treinamento (que coletam dados para treinar modelos de linguagem). Bloquear um bot de busca remove o site das respostas da IA. Bloquear um bot de treinamento apenas impede que o conteúdo entre no conjunto de treinamento – sem afetar visibilidade nas respostas. Nenhum guia PT-BR faz essa distinção com clareza.
Bots de busca e indexação: rastreiam seu site para indexar e servir conteúdo nas respostas dos motores de IA. Se você quer aparecer no ChatGPT Search ou no Perplexity, precisa permitir esses bots. São bots que trabalham como o Googlebot – mas para IAs.
Bots de treinamento: coletam conteúdo para treinar os modelos de linguagem. Bloquear esses bots não afeta se você aparece nas respostas da IA – só afeta se seu conteúdo entra no conjunto de treinamento.
Bots de busca e indexação: quais permitir para aparecer nas respostas de IA
Dados da Search Engine Journal (dez/2025):
| Bot | Empresa | Para que serve | Taxa de crawl | User-agent string | IPs verificados |
|---|---|---|---|---|---|
| ChatGPT-User | OpenAI | Navegação em tempo real quando usuário usa ChatGPT | 2.400 páginas/hora | compatible; ChatGPT-User/1.0; +https://openai.com/bot | openai.com/chatgpt-user.json |
| OAI-SearchBot | OpenAI | Indexação para ChatGPT Search (não treinamento) | 150 páginas/hora | compatible; OAI-SearchBot/1.3; +https://openai.com/searchbot | openai.com/searchbot.json |
| PerplexityBot | Perplexity | Indexação para o answer engine | 150 páginas/hora | compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot | perplexity.com/perplexitybot.json |
| Perplexity-User | Perplexity | Navegação em tempo real por consulta do usuário | menos de 10/hora | compatible; Perplexity-User/1.0; +https://perplexity.ai/perplexity-user | perplexity.com/perplexity-user.json |
| ClaudeBot | Anthropic | Indexação para Claude (e treinamento) | 500 páginas/hora | compatible; ClaudeBot/1.0; +claudebot@anthropic.com | docs.claude.com |
| Claude-SearchBot | Anthropic | Indexação para capacidades de busca do Claude | menos de 10/hora | compatible; Claude-SearchBot/1.0; +https://www.anthropic.com | Não disponível |
| Bingbot | Microsoft | Bing Search e Microsoft Copilot | 1.300 páginas/hora | compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm | bing.com/toolbox/bingbot.json |
| Gemini-Deep-Research | Agente do Gemini para pesquisa aprofundada | menos de 10/hora | compatible; Gemini-Deep-Research; +https://gemini.google/overview/deep-research/ | googlebot.json |
Sobre o ChatGPT-User: 2.400 páginas/hora é 16 vezes mais rápido que o GPTBot de treinamento. É o bot mais ativo da OpenAI em sites externos hoje. Se você usa logs de servidor, provavelmente já viu passagens dele.
Bots de treinamento: o que você pode escolher bloquear
| Bot | Empresa | Para que serve | User-agent string |
|---|---|---|---|
| GPTBot | OpenAI | Treinar modelos GPT (ChatGPT, GPT-4o, GPT-5) | compatible; GPTBot/1.3; +https://openai.com/gptbot |
| ClaudeBot | Anthropic | Treinar modelos Claude (aparece nos dois grupos) | compatible; ClaudeBot/1.0; +claudebot@anthropic.com |
| anthropic-ai | Anthropic | Token de treinamento adicional da Anthropic | anthropic-ai |
| CCBot | Common Crawl | Conjunto de dados usado por múltiplas empresas de IA | CCBot/2.0 |
| Meta-ExternalAgent | Meta | Treinar LLMs da Meta (Llama) | meta-externalagent/1.1 |
| Google-Extended | Token (não crawler) que controla uso para treinamento Google | Google-Extended |
O que acontece quando um bot de IA é bloqueado pelo robots.txt?
Quando um bot é bloqueado pelo robots.txt, ele para de rastrear o site – e as consequências dependem do tipo de bot. Bloquear um bot de busca (ChatGPT-User, OAI-SearchBot, PerplexityBot) remove o site do índice daquele motor de IA: as respostas que poderiam citar sua marca passam a citar concorrentes. Bloquear um bot de treinamento (GPTBot, CCBot) apenas impede que seu conteúdo entre no próximo ciclo de treinamento, sem afetar respostas em tempo real.
Atenção ao ClaudeBot: aparece nos dois grupos. Ele faz tanto indexação (para responder usuários do Claude) quanto coleta para treinamento. Bloquear ClaudeBot remove seu site tanto do conjunto de treinamento quanto das respostas do Claude.
O que o mercado está fazendo hoje: 79% dos principais sites de notícias bloqueiam pelo menos um bot de treinamento. GPTBot está bloqueado em 62% desses sites, CCBot em 75%. Mas 67% bloqueiam o PerplexityBot – um bot de busca, não de treinamento – provavelmente sem entender a consequência.
Apenas 8,92% dos top 10 mil domínios têm alguma regra de bloqueio para bots de IA. A maioria das empresas brasileiras ainda não tomou nenhuma decisão sobre isso – o que na prática significa que está permitindo tudo.
Como escrever seu robots.txt para IA
Configurar o robots.txt para bots de IA exige decidir entre três cenários: permitir tudo, bloquear só treinamento, ou bloquear tudo exceto o Google. A escolha certa depende do objetivo da marca – aparecer no máximo de IAs, proteger dados de treinamento, ou restringir visibilidade ao Google. Os três templates abaixo cobrem cada cenário com código pronto para copiar.
Template 1: Permitir tudo (máxima visibilidade em IA)
# Permite todos os crawlers de busca e IA
User-agent: *
Allow: /
Sitemap: https://seusite.com.br/sitemap.xmlQuando usar: você quer aparecer no máximo de IAs possível e está confortável com uso do seu conteúdo para treinamento. É o padrão quando não existe robots.txt - a diferença é que esse arquivo documenta a intenção explicitamente.Template 2: Bloquear treinamento, permitir busca
Esse é o template que a maioria das empresas brasileiras deveria usar, mas quase nenhuma tem.
# Permite todos os crawlers de busca e IA de busca
User-agent: *
Allow: /
# Bloqueia crawlers de treinamento de IA
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
Sitemap: https://seusite.com.br/sitemap.xmlQuando usar: você quer aparecer no ChatGPT Search, Perplexity e AI Overviews, mas prefere que seu conteúdo não seja usado para treinar modelos. Você continua rastreável pelos bots de busca (ChatGPT-User, OAI-SearchBot, PerplexityBot, Bingbot) e só bloqueia os que fazem coleta para treinamento.
Nota: esse template não inclui ClaudeBot porque bloquear ClaudeBot também remove você das respostas do Claude. Avalie se faz sentido para o seu caso.
Também não inclui Google-Extended porque não é um crawler – é um token de produto. Adicionar User-agent: Google-Extended / Disallow: / não afeta seu rastreamento pela Google, apenas impede o uso para treinar modelos Google.
Template 3: Bloquear tudo exceto Google
# Bloqueia todos os crawlers
User-agent: *
Disallow: /
# Permite apenas Googlebot
User-agent: Googlebot
Allow: /
Sitemap: https://seusite.com.br/sitemap.xmlQuando usar: raramente. Só quando você quer aparecer exclusivamente no Google e em nenhuma outra IA. Esse template remove seu site do ChatGPT Search, Perplexity, Bing/Copilot e Claude.Como verificar e testar seu robots.txt
Duas formas de checar:
- Acesse
seudominio.com.br/robots.txtdiretamente no browser. Se carregar um arquivo de texto, ele existe. Se der 404, não existe. - Google Search Console: Configurações → robots.txt – mostra o conteúdo atual e permite testar regras específicas.
Para ver quais bots de IA visitaram seu site: acesse os logs brutos do servidor e busque pelas strings de user-agent da tabela acima. O Google Search Console mostra rastreamentos do Googlebot, mas não dos outros bots de IA. Para cobertura completa, você precisa dos logs ou de uma ferramenta de monitoramento.
Para monitorar se sua marca está aparecendo nas respostas das IAs depois de configurar o robots.txt, ferramentas como a Tropk.ai medem visibilidade em ChatGPT, Perplexity e Google AI Overviews – e mostram se as mudanças técnicas estão tendo efeito.
Além do robots.txt: llms.txt e o que vem por aí
O robots.txt controla quem pode rastrear o site, mas não orienta o que os LLMs devem priorizar ao indexar. Para isso surgem dois padrões complementares em adoção gradual: llms.txt e RSL (Really Simple Licensing).
llms.txt foi proposto por Jeremy Howard (fast.ai) em setembro de 2024. É um arquivo Markdown em /llms.txt que funciona como “sitemap para LLMs” – uma curadoria dos conteúdos mais importantes do site em formato legível por modelos de linguagem. Diferente do robots.txt: não controla acesso. Orienta LLMs sobre o que priorizar quando rastreiam seu site. A Anthropic já implementou no próprio site. Adoção ainda limitada em 2026, mas vai crescer. Veja a documentação em llmstxt.org.
RSL (Really Simple Licensing) foi lançado em 2025 pela RSL Collective, com Medium, Reddit e Yahoo entre os fundadores. Permite que publishers definam termos de uso do conteúdo para bots de IA via robots.txt – uma licença legível por máquina embutida no arquivo. A lógica é dar mais controle sobre como o conteúdo pode ser usado, além do simples allow/disallow.
Para a maioria das empresas brasileiras, configurar bem o robots.txt já é um passo muito acima do que a concorrência está fazendo. llms.txt e RSL são próximos passos para quem quer controle mais fino.
Veja nosso guia técnico completo de otimização para visibilidade em IA para ir além do robots.txt: schema markup, estrutura semântica e o que mais impacta sua presença nas respostas de ChatGPT e Perplexity.
Descubra como sua marca aparece hoje no ChatGPT, Perplexity e Google AI Overviews. A Tropk.ai mede sua visibilidade em IA e mostra o que está impedindo que você apareça nas respostas que importam.
FAQ
Como ver o robots.txt do meu site?
Acesse seudominio.com.br/robots.txt diretamente no browser. Se carregar um arquivo de texto, ele existe e está ativo. Se retornar 404, o arquivo não existe – o que significa que todos os crawlers têm acesso a tudo por padrão. Você também pode checar no Google Search Console em Configurações → robots.txt.
Bloquear o GPTBot remove meu site do ChatGPT?
Não diretamente. GPTBot é o bot de treinamento da OpenAI: coleta dados para treinar modelos como GPT-4o e GPT-5, não para responder usuários. Bloquear GPTBot impede que seu conteúdo entre no treinamento. Para remover seu site do ChatGPT Search, você precisaria bloquear OAI-SearchBot e ChatGPT-User – os bots responsáveis por indexação e respostas em tempo real.
O Google-Extended afeta meus AI Overviews?
Não. Google-Extended não é um crawler – é um token de produto que controla se o Googlebot pode usar os dados coletados para treinar modelos de IA da Google. Bloquear Google-Extended não afeta em nada sua presença nos AI Overviews ou seu ranking na busca tradicional. Para aparecer nos AI Overviews, o Googlebot precisa ter acesso ao seu site – e o Google-Extended não controla isso.
O que acontece se eu não tiver um arquivo robots.txt?
Nada muda automaticamente. Sem o arquivo, todos os crawlers têm acesso a todo o conteúdo do site por padrão. Do ponto de vista de visibilidade em IA, não ter robots.txt é equivalente a ter User-agent: * Allow: /. Se você quer bloquear bots de treinamento, precisará criar o arquivo explicitamente.
Como ver quais bots de IA visitaram meu site?
Nos logs do servidor. Procure pelas strings de user-agent listadas nas tabelas deste artigo – por exemplo GPTBot/1.3, PerplexityBot/1.0, ChatGPT-User/1.0. O Google Search Console mostra rastreamentos do Googlebot, mas não de outros bots de IA. Para uma visão completa, você precisa de acesso aos logs brutos ou de uma ferramenta de análise de bots.
PerplexityBot respeita o robots.txt?
Oficialmente sim. Em 2024, relatórios indicaram que a Perplexity ignorava robots.txt em alguns casos – a empresa disse que corrigiu o comportamento. Mas 67% dos principais sites de notícias bloqueiam o PerplexityBot hoje, muitos sem entender que estão removendo o próprio site das citações do Perplexity. Se você quer garantir que o Perplexity acesse seu site, inclua explicitamente User-agent: PerplexityBot / Allow: / mesmo quando o bloco geral já permite tudo.
Posso bloquear alguns bots de IA mas não outros?
Sim. O robots.txt foi projetado exatamente para isso. Você pode ter regras específicas para cada user-agent. A regra User-agent: * se aplica apenas aos bots que não têm regra específica. O Template 2 deste artigo mostra exatamente como fazer: bloquear GPTBot, CCBot, anthropic-ai e Meta-ExternalAgent enquanto mantém ChatGPT-User, OAI-SearchBot e PerplexityBot com acesso completo.

